
If you are an SEO practitioner or digital marketer reading this article, you may have experimented with AI and chatbots in your everyday work.
But the question is, how can you make the most out of AI other than using a chatbot user interface?
For that, you need a profound understanding of how large language models (LLMs) work and learn the basic level of coding. And yes, coding is absolutely necessary to succeed as an SEO professional nowadays.
This is the first of a series of articles that aim to level up your skills so you can start using LLMs to scale your SEO tasks. We believe that in the future, this skill will be required for success.
We need to start from the basics. It will include essential information, so later in this series, you will be able to use LLMs to scale your SEO or marketing efforts for the most tedious tasks.
Contrary to other similar articles you’ve read, we will start here from the end. The video below illustrates what you will be able to do after reading all the articles in the series on how to use LLMs for SEO.
Our team uses this tool to make internal linking faster while maintaining human oversight.
Did you like it? This is what you will be able to build yourself very soon.
Now, let’s start with the basics and equip you with the required background knowledge in LLMs.
What Are Vectors?
In mathematics, vectors are objects described by an ordered list of numbers (components) corresponding to the coordinates in the vector space.
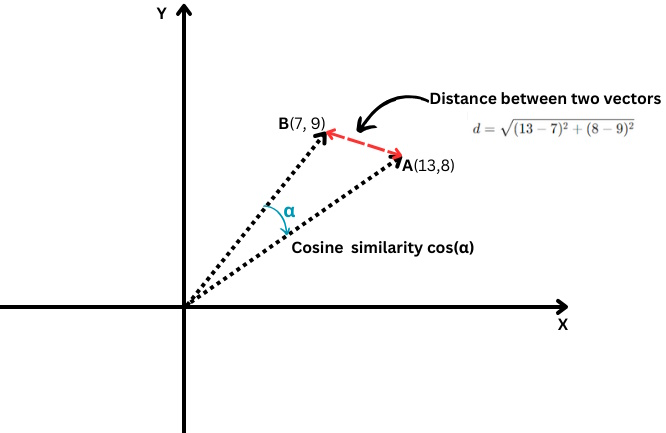
A simple example of a vector is a vector in two-dimensional space, which is represented by (x,y) coordinates as illustrated below.
In this case, the coordinate x=13 represents the length of the vector’s projection on the X-axis, and y=8 represents the length of the vector’s projection on the Y-axis.
Vectors that are defined with coordinates have a length, which is called the magnitude of a vector or norm. For our two-dimensional simplified case, it is calculated by the formula:
However, mathematicians went ahead and defined vectors with an arbitrary number of abstract coordinates (X1, X2, X3 … Xn), which is called an “N-dimensional” vector.
In the case of a vector in three-dimensional space, that would be three numbers (x,y,z), which we can still interpret and understand, but anything above that is out of our imagination, and everything becomes an abstract concept.
And here is where LLM embeddings come into play.
What Is Text Embedding?
Text embeddings are a subset of LLM embeddings, which are abstract high-dimensional vectors representing text that capture semantic contexts and relationships between words.
In LLM jargon, “words” are called data tokens, with each word being a token. More abstractly, embeddings are numerical representations of those tokens, encoding relationships between any data tokens (units of data), where a data token can be an image, sound recording, text, or video frame.
In order to calculate how close words are semantically, we need to convert them into numbers. Just like you subtract numbers (e.g., 10-6=4) and you can tell that the distance between 10 and 6 is 4 points, it is possible to subtract vectors and calculate how close the two vectors are.
Thus, understanding vector distances is important in order to grasp how LLMs work.
There are different ways to measure how close vectors are:
- Euclidean distance.
- Cosine similarity or distance.
- Jaccard similarity.
- Manhattan distance.
Each has its own use cases, but we will discuss only commonly used cosine and Euclidean distances.
What Is The Cosine Similarity?
It measures the cosine of the angle between two vectors, i.e., how closely those two vectors are aligned with each other.
 Euclidean distance vs. cosine similarity
Euclidean distance vs. cosine similarityIt is defined as follows:
Where the dot product of two vectors is divided by the product of their magnitudes, a.k.a. lengths.
Its values range from -1, which means completely opposite, to 1, which means identical. A value of ‘0’ means the vectors are perpendicular.
In terms of text embeddings, achieving the exact cosine similarity value of -1 is unlikely, but here are examples of texts with 0 or 1 cosine similarities.
Cosine Similarity = 1 (Identical)
- “Top 10 Hidden Gems for Solo Travelers in San Francisco”
- “Top 10 Hidden Gems for Solo Travelers in San Francisco”
?These texts are identical, so their embeddings would be the same, resulting in a cosine similarity of 1.
Cosine Similarity = 0 (Perpendicular, Which Means Unrelated)
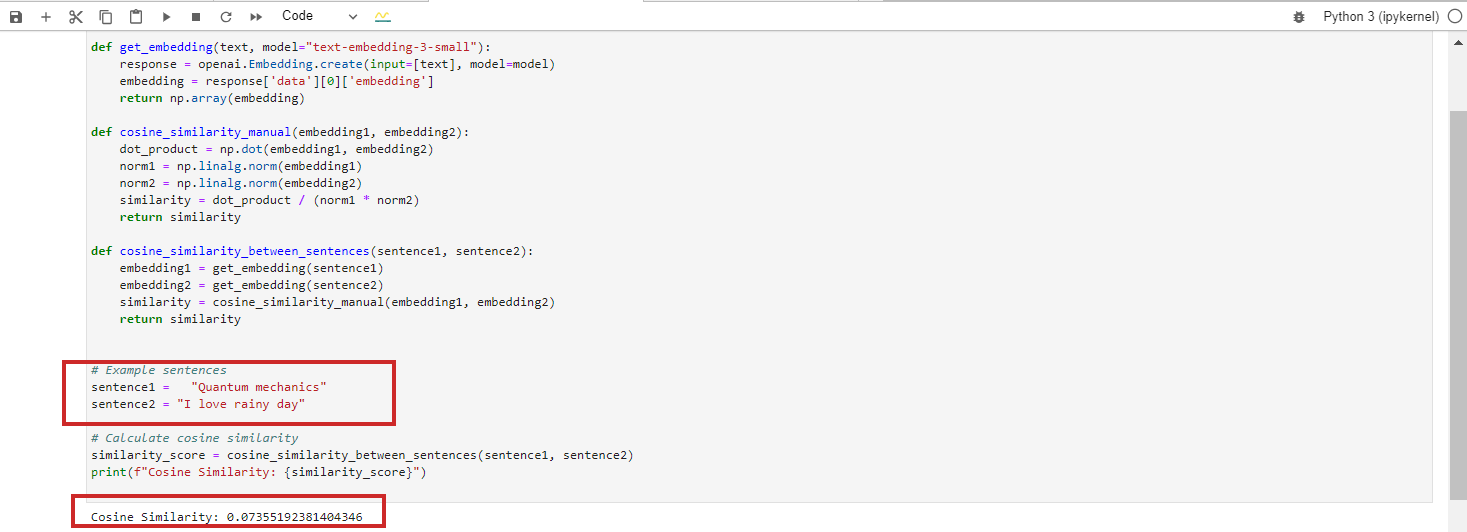
- “Quantum mechanics”
- “I love rainy day”
?These texts are totally unrelated, resulting in a cosine similarity of 0 between their BERT embeddings.
However, if you run Google Vertex AI’s embedding model ‘text-embedding-preview-0409’, you will get 0.3. With OpenAi’s ‘text-embedding-3-large’ models, you will get 0.017.
(Note: We will learn in the next chapters in detail practicing with embeddings using Python and Jupyter).

We are skipping the case with cosine similarity = -1 because it is highly unlikely to happen.
If you try to get cosine similarity for text with opposite meanings like “love” vs. “hate” or “the successful project” vs. “the failing project,” you will get 0.5-0.6 cosine similarity with Google Vertex AI’s ‘text-embedding-preview-0409’ model.
It is because the words “love” and “hate” often appear in similar contexts related to emotions, and “successful” and “failing” are both related to project outcomes. The contexts in which they are used might overlap significantly in the training data.
Cosine similarity can be used for the following SEO tasks:
- Classification.
- Keyword clustering.
- Implementing redirects.
- Internal linking.
- Duplicate content detection.
- Content recommendation.
- Competitor analysis.
Cosine similarity focuses on the direction of the vectors (the angle between them) rather than their magnitude (length). As a result, it can capture semantic similarity and determine how closely two pieces of content align, even if one is much longer or uses more words than the other.
Deep diving and exploring each of these will be a goal of upcoming articles we will publish.
What Is The Euclidean Distance?
In case you have two vectors A(X1,Y1) and B(X2,Y2), the Euclidean distance is calculated by the following formula:
It is like using a ruler to measure the distance between two points (the red line in the chart above).
Euclidean distance can be used for the following SEO tasks:
- Evaluating keyword density in the content.
- Finding duplicate content with a similar structure.
- Analyzing anchor text distribution.
- Keyword clustering.
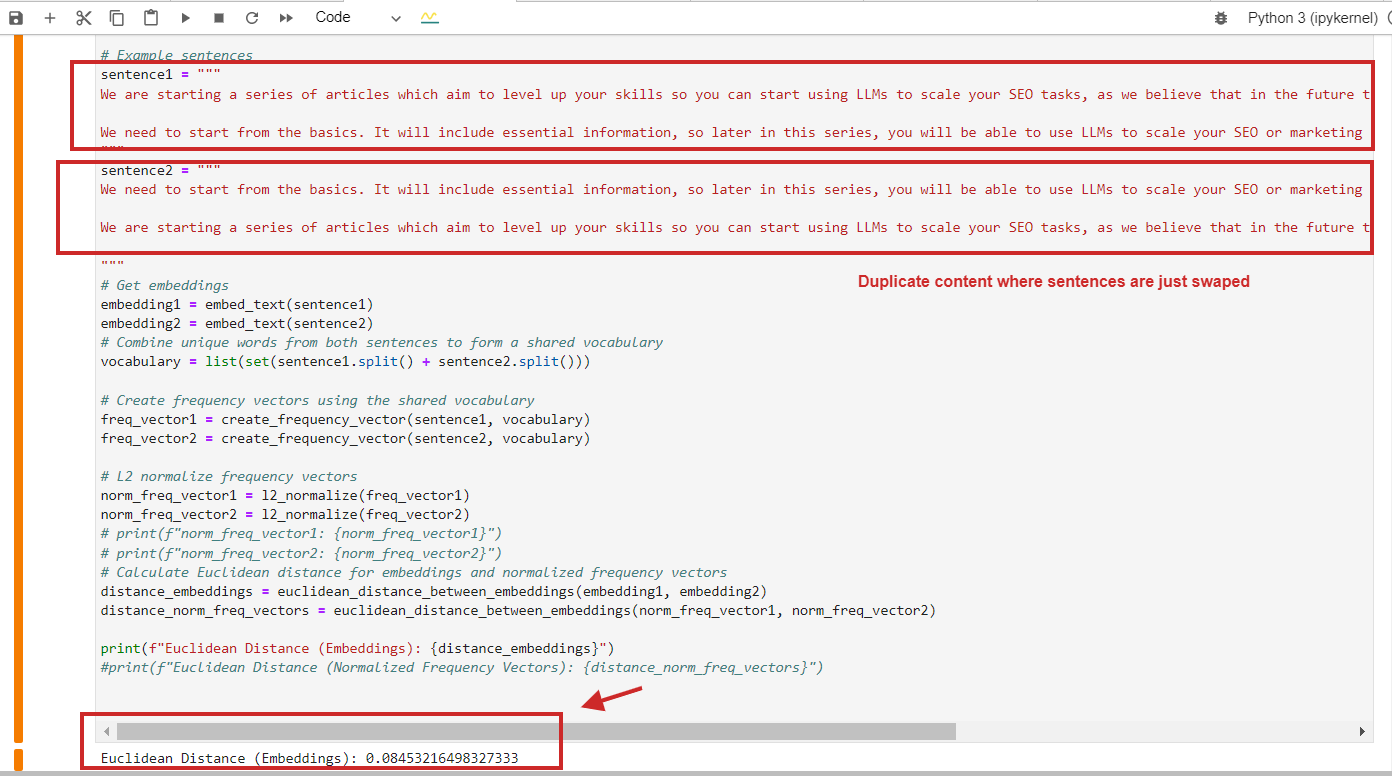
Here is an example of Euclidean distance calculation with a value of 0.08, nearly close to 0, for duplicate content where paragraphs are just swapped – meaning the distance is 0, i.e., the content we compare is the same.
 Euclidean distance calculation example of duplicate content
Euclidean distance calculation example of duplicate contentOf course, you can use cosine similarity, and it will detect duplicate content with cosine similarity 0.9 out of 1 (almost identical).
Here is a key point to remember: You should not merely rely on cosine similarity but use other methods, too, as Netflix’s research paper suggests that using cosine similarity can lead to meaningless “similarities.”
We show that cosine similarity of the learned embeddings can in fact yield arbitrary results. We find that the underlying reason is not cosine similarity itself, but the fact that the learned embeddings have a degree of freedom that can render arbitrary cosine-similarities.
As an SEO professional, you don’t need to be able to fully comprehend that paper, but remember that research shows that other distance methods, such as the Euclidean, should be considered based on the project needs and outcome you get to reduce false-positive results.
What Is L2 Normalization?
L2 normalization is a mathematical transformation applied to vectors to make them unit vectors with a length of 1.
To explain in simple terms, let’s say Bob and Alice walked a long distance. Now, we want to compare their directions. Did they follow similar paths, or did they go in completely different directions?
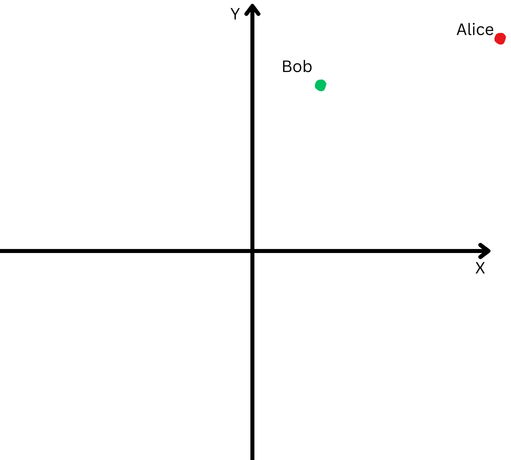 “Alice” is represented by a red dot in the upper right quadrant, and “Bob” is represented by a green dot.
“Alice” is represented by a red dot in the upper right quadrant, and “Bob” is represented by a green dot.However, since they are far from their origin, we will have difficulty measuring the angle between their paths because they have gone too far.
On the other hand, we can’t claim that if they are far from each other, it means their paths are different.
L2 normalization is like bringing both Alice and Bob back to the same closer distance from the starting point, say one foot from the origin, to make it easier to measure the angle between their paths.
Now, we see that even though they are far apart, their path directions are quite close.
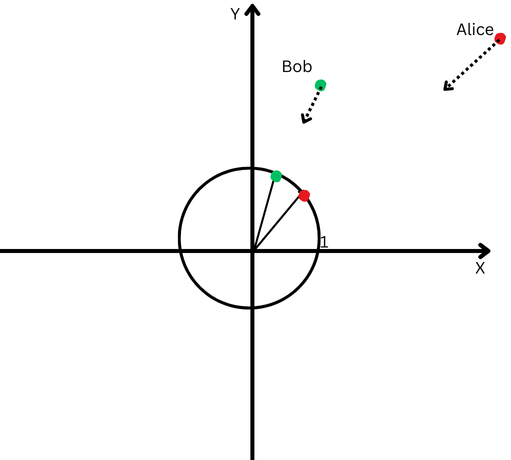 A Cartesian plane with a circle centered at the origin.
A Cartesian plane with a circle centered at the origin.This means that we’ve removed the effect of their different path lengths (a.k.a. vectors magnitude) and can focus purely on the direction of their movements.
In the context of text embeddings, this normalization helps us focus on the semantic similarity between texts (the direction of the vectors).
Most of the embedding models, such as OpeanAI’s ‘text-embedding-3-large’ or Google Vertex AI’s ‘text-embedding-preview-0409’ models, return pre-normalized embeddings, which means you don’t need to normalize.
But, for example, BERT model ‘bert-base-uncased’ embeddings are not pre-normalized.
Conclusion
This was the introductory chapter of our series of articles to familiarize you with the jargon of LLMs, which I hope made the information accessible without needing a PhD in mathematics.
If you still have trouble memorizing these, don’t worry. As we cover the next sections, we will refer to the definitions defined here, and you will be able to understand them through practice.
The next chapters will be even more interesting:
- Introduction To OpenAI’s Text Embeddings With Examples.
- Introduction To Google’s Vertex AI Text Embeddings With Examples.
- Introduction To Vector Databases.
- How To Use LLM Embeddings For Internal Linking.
- How To Use LLM Embeddings For Implementing Redirects At Scale.
- Putting It All Together: LLMs-Based WordPress Plugin For Internal Linking.
The goal is to level up your skills and prepare you to face challenges in SEO.
Many of you may say that there are tools you can buy that do these types of things automatically, but those tools will not be able to perform many specific tasks based on your project needs, which require a custom approach.
Using SEO tools is always great, but having skills is even better!
More resources:
Featured Image: Krot_Studio/Shutterstock




